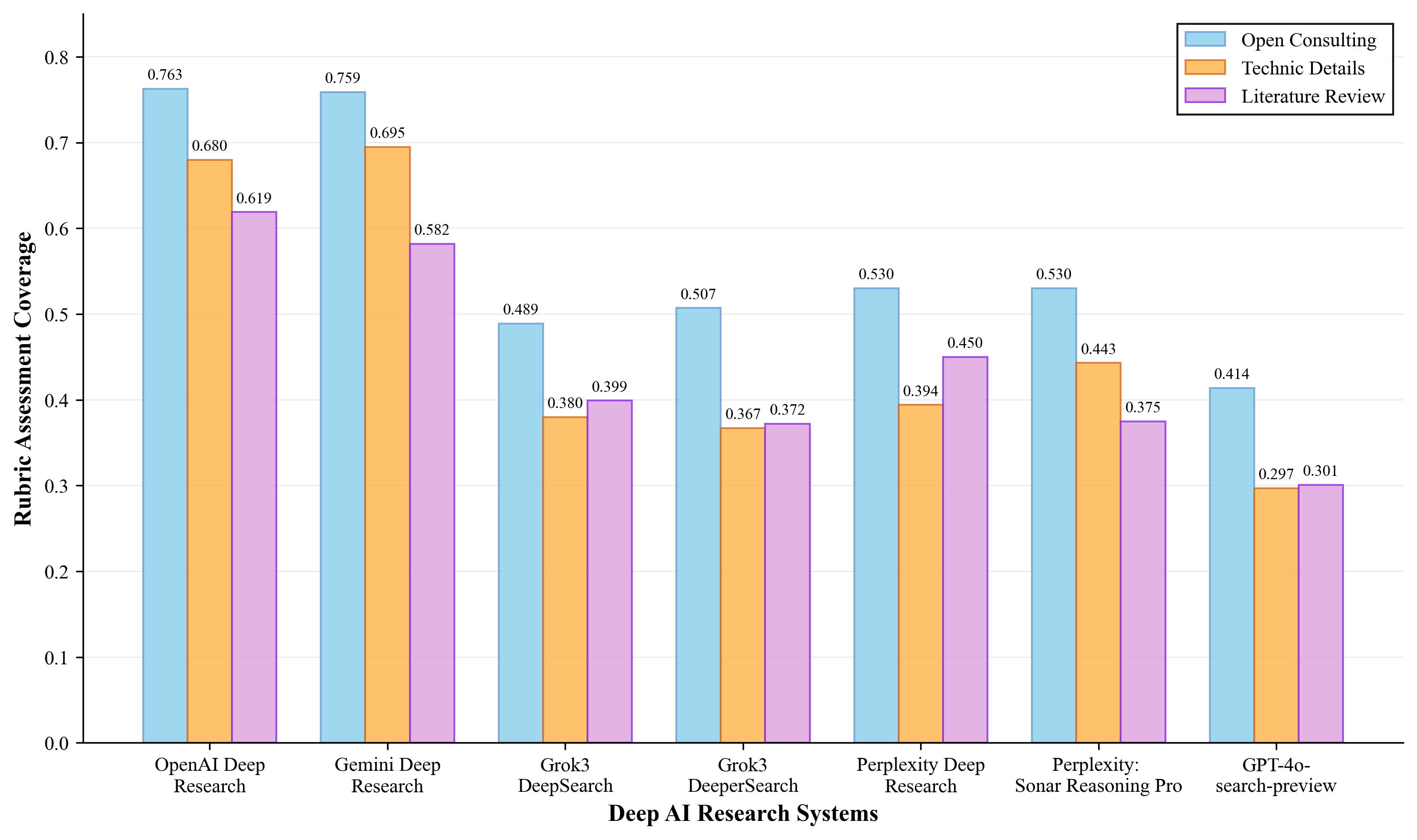
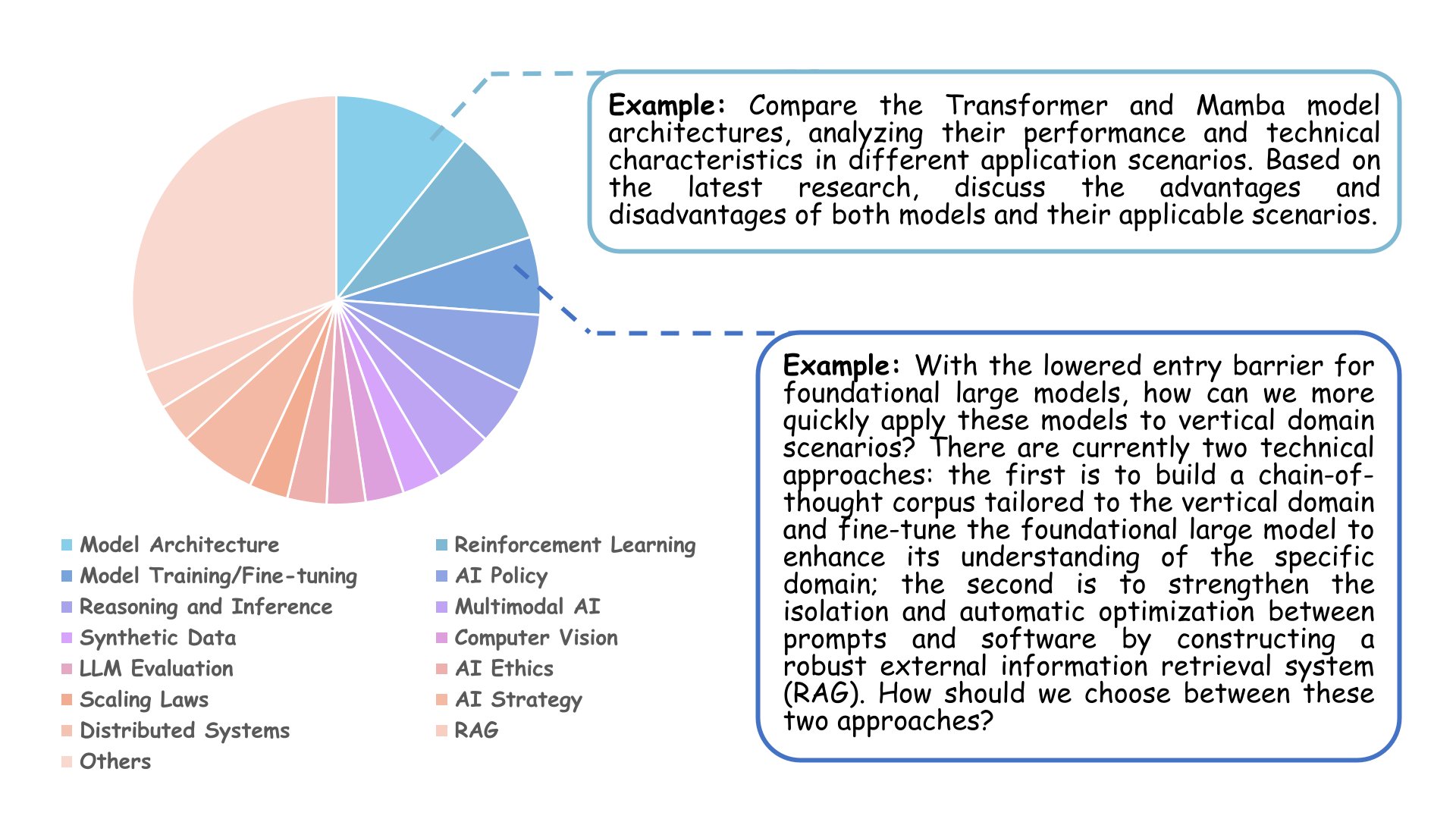
We evaluate various Deep AI Research Systems (DARS), including leading commercial platforms and baseline systems with web search capabilities. Our evaluation focuses on three question types: Technical Details, Literature Review, and Open Consulting questions across 35 AI research subjects.
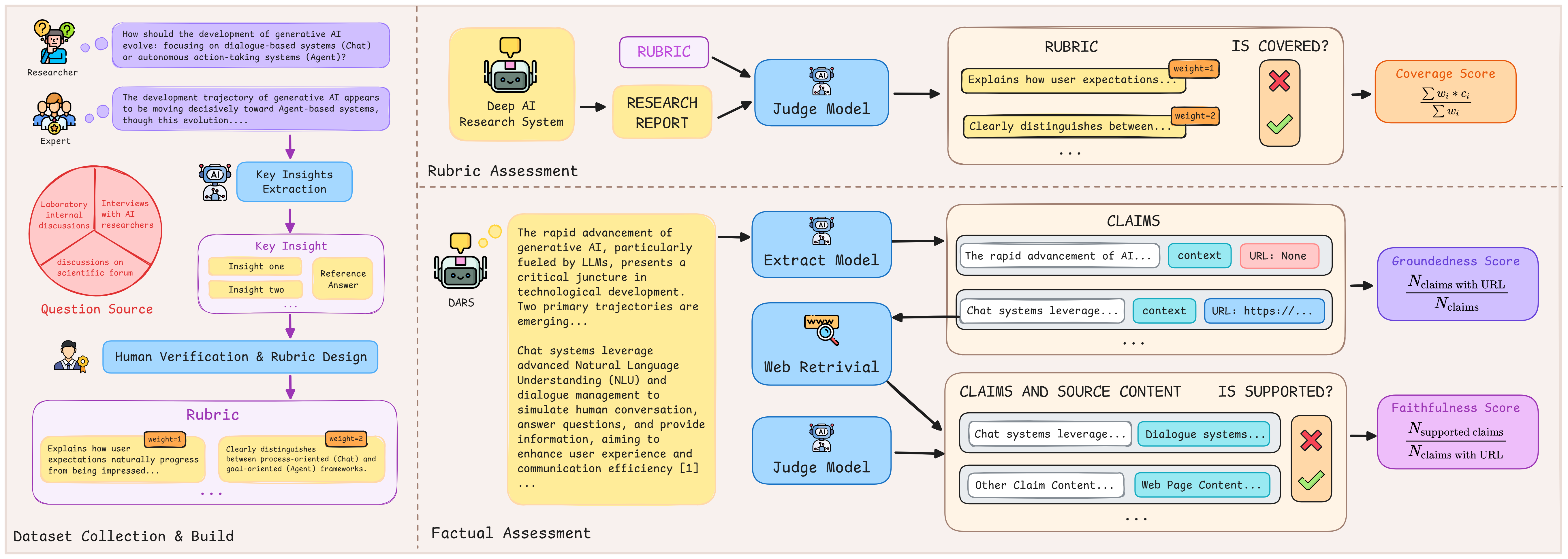
The evaluation employs our dual assessment framework: Rubric Assessment measures insight quality using expert-designed criteria, while Factual Assessment evaluates citation accuracy (Faithfulness) and coverage (Groundedness). All experiments were conducted between March and June 2025 to ensure temporal consistency.
Note: Results show that DARS systems demonstrate particular strength in open consulting questions, suggesting their potential as innovative research ideation partners rather than precision technical implementation guides.